DocuData converts PDFs, scans, and office files into structured JSON or CSV— automatically. No more manual rekeying, no more copy-paste, no brittle scripts. Just consistent, machine-ready data your systems can trust.
A quick look at how DocuData turns messy documents into structured, usable data.

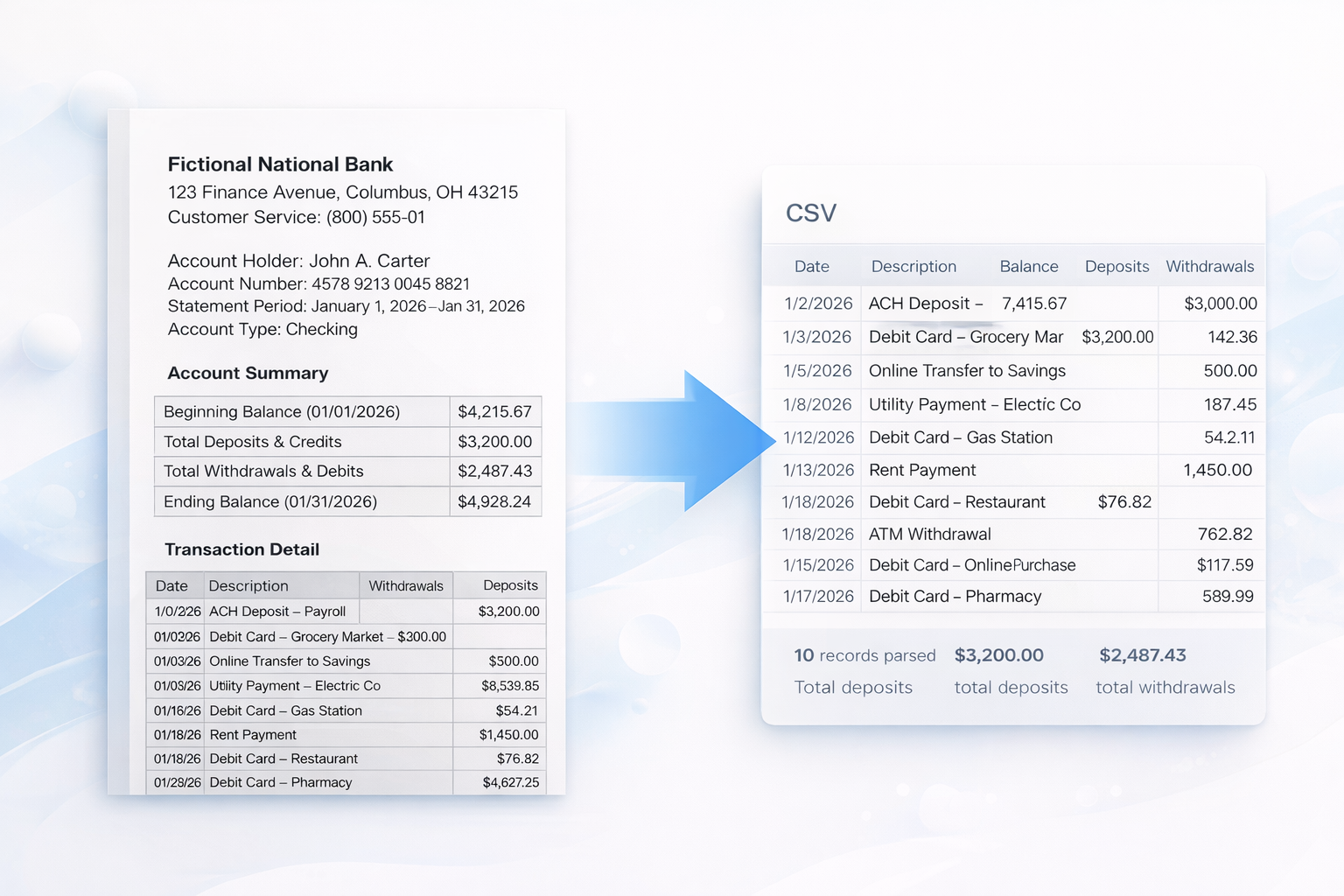
DocuData is built for teams who rely on documents but need structured, predictable output. Upload a PDF—or send it via API—and get clean JSON or CSV every time.


Map each document layout once. DocuData reuses the template so recurring vendors, invoices, statements, and reports extract perfectly every time.
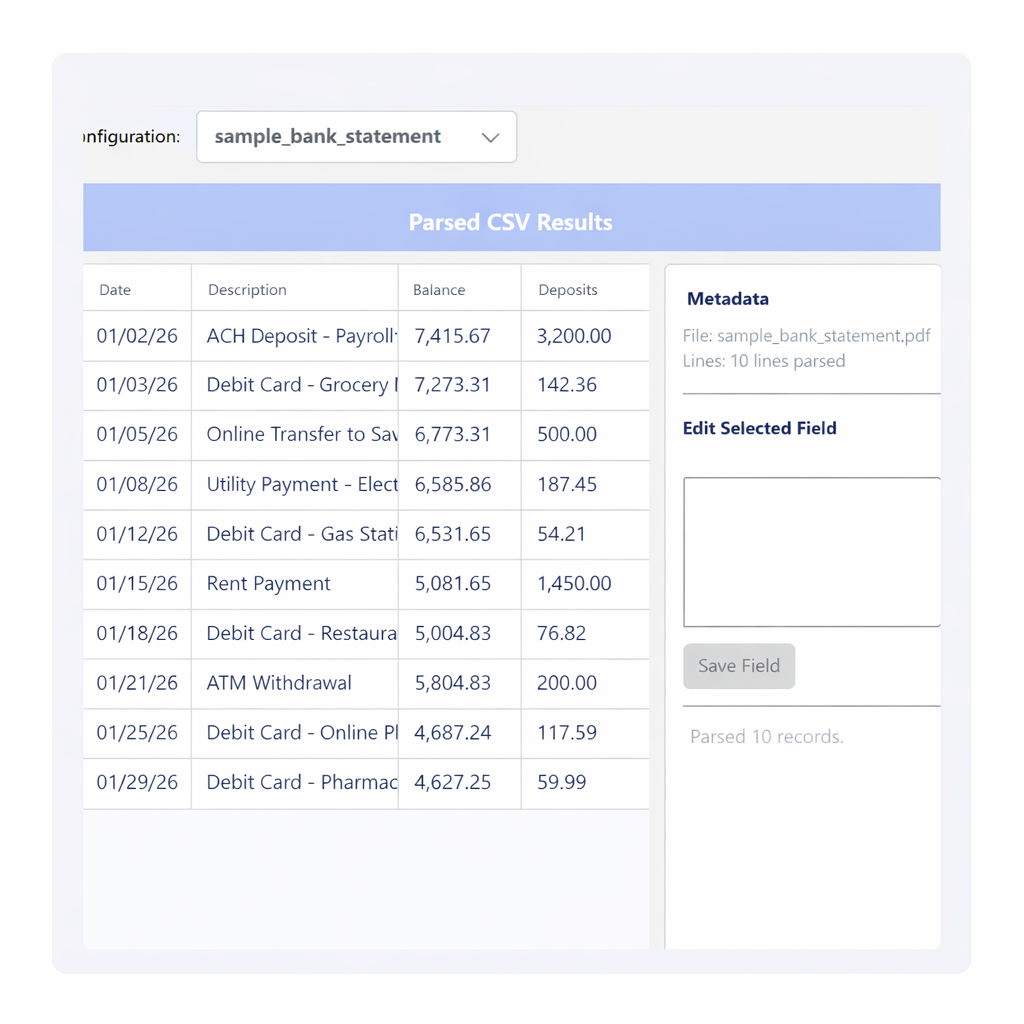
Enforce required fields, check totals, ensure formats match expectations, and catch broken documents before they hit your system.
Drop DocuData into your existing workflow: send a file, get structured data back. No UI overhaul. No new systems to train users on.

Consistent fields, repeatable extraction, no more guessing where the data lives.

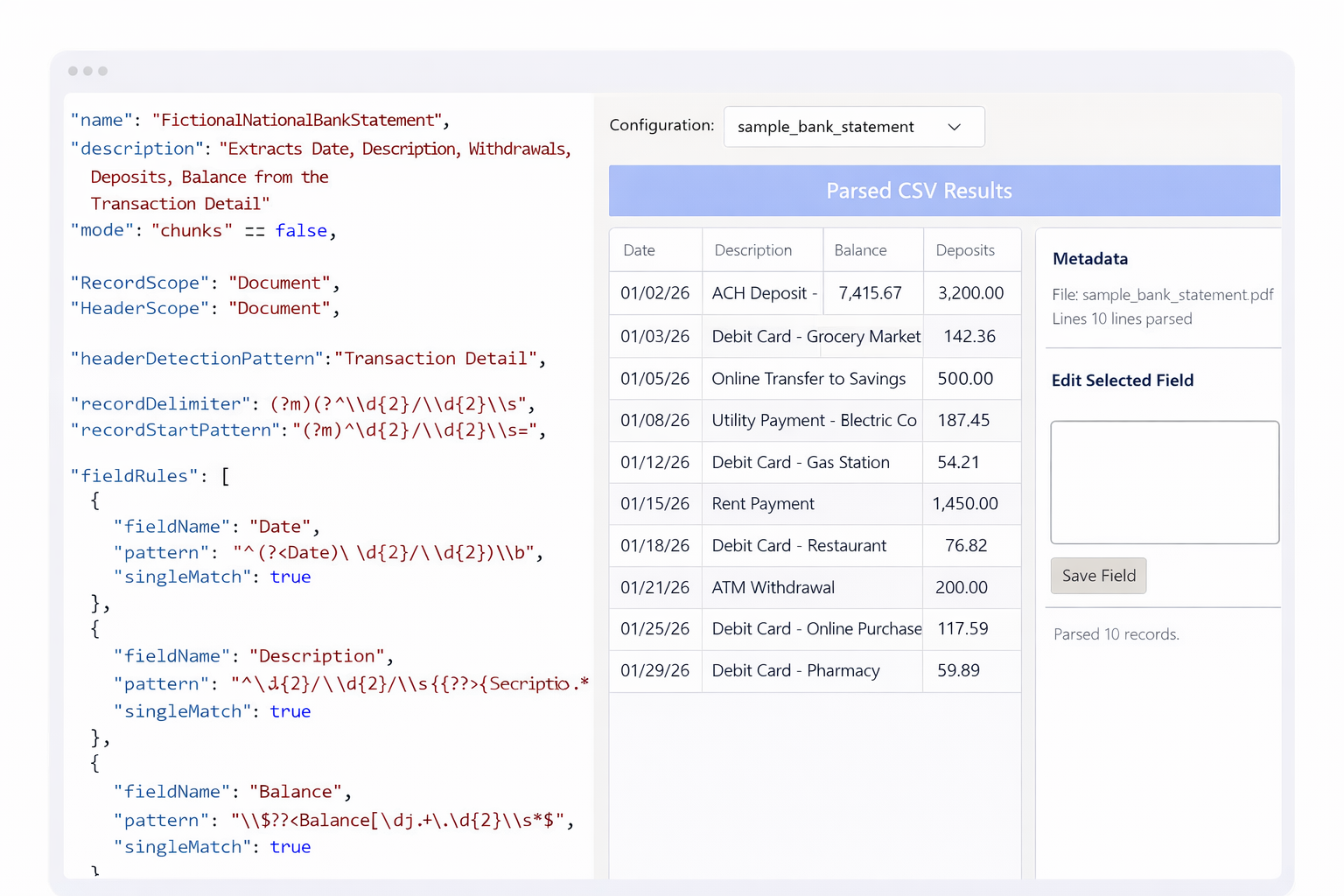
Build extraction templates once; reuse them across thousands of documents.

Skip the learning curve and go straight to production.

100% on-device processing. Documents never leave your machine.
Less manual data entry
Typical time to production
Rating (4.8/5.0)
User retraining needed
Try DocuData on your own PDFs, or talk with our implementation team to see how fast it can integrate with your systems.
